R For SEO Part 4: Functions
Welcome back to part four of my series on using R for SEO. We’re at the halfway point now and hopefully you’re starting to see the power that the R language can bring to your optimisation and analysis.
Today we’re going to start making it feel like we’re programming – we’re going to be writing our own R functions, looking at the anatomy of a function and creating a few of the most common ones that I use in my SEO work.
I know, again, that this piece is super late. The last eighteen months has been a lot, but hopefully the next few months will give me more time.
As always, shares of this piece are highly appreciated, and if you’d like updates on when I drop new content, please sign up for my FREE email list using the form below.
Ready to go?
R Functions
Functions in R or any other programming language are basically commands. Every command we’ve used up until this point has included a function of some description. Think of them like Excel formulae.
But the advantage of programming is that we’re not limited to the ones that come in the box – we can create our own. This is where using R starts to feel like it’s real programming rather than just running a series of commands in a terminal, and when I started using it, functions were where it all really started to click.
The beauty of a function is that you can make it variable and, consequently, use it over and over again rather than writing the same commands constantly over the course of your analysis, and you can copy and paste them from one .R file into another and they’ll still work.
An R function can be as simple or as complex as you need it to be. You can make an entire piece of analysis run from one function if you need it to, but there are a few core elements that you should always be aware of.
Our First R Function
Again, an R function can be as simple or as complex as you need it to be, but the anatomy of that function will always have similarities.
Let’s create a really simple function first, and then we’ll break it down.
firstFun <- function(x,y){
x*y
}
This is a very basic function that will multiply one value (x) by another value (y). Truth be told, we don’t need an R function for this, but it’s an easy illustration for our first one.
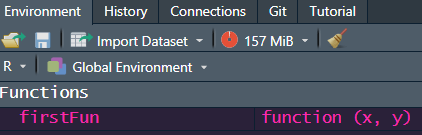
Paste this function into your console and now you’ll see “firstFun” in your environment explorer under “Functions”, like so:
Now to run it, we can simply type the following in our console:
firstFun(5,2)
Hit return and you’ll see the following output in your console:

Nice and simple.
And if we wanted to turn it into an object, we could use the following:
firstFunRun <- firstFun(5,2)
Paste that into your console and you’ll see that firstFunRun is now in your environment.
And again, if you type firstFunRun into your console and hit return, you’ll see the same output as above.
The beauty of using this as a function is the variables (x and y, in this case), meaning we can put any value we like in their place when running the function. Try it yourself.
Now we’ve made our first function, let’s expand it a little.
Expanding Our First Function
Here’s how we could make this function a little bit more varied and incorporate some additional values:
secondFun <- function(x,y){
val1 <- x*y
val2 <- x+y
val3 <- x-y
val4 <- x/y
output <- data.frame(val1,val2,val3,val4)
}
So now we’ve made our function ever so slightly more complex and included a few more values, with the idea of exporting all these permutations of our original calculation in one go. This is where a function would be a bit more useful.
As before, paste this into your console. Now use the same command as before:
secFunRun <- secondFun(5,2)
And when we type secFunRun into our console and hit return, we’ll get the following:

Editing Column Names In An R Function
It’s starting to come together. Now let’s edit our secondFun function to add column headers so we know which value is which.
secondFun <- function(x,y){
val1 <- x*y
val2 <- x+y
val3 <- x-y
val4 <- x/y
output <- data.frame(val1,val2,val3,val4)
colnames(output) <- c("multiply", "add", "subtract", "divide")
return(output)
}
Paste that into your console and run the same command again, and your output will be updated to show the following:

As you may have guessed here, we don’t really need that “names” section there, we could’ve just named the elements that way in the first place, but it was just an example to show you how you can rename columns in a data frame in R.
Again, try it yourself a little. Now let’s look at the anatomy of that final R function and how we build them.
The Anatomy Of An R Function
Again, your functions can be as simple or as complex as you need them to be, but there are some common elements:
- secondFun <- function: Here, we’re telling R that we’re creating something called “secondFun” and it’s a function
- (x,y): The number of variables required by the function. You can add as many as you want, but it’s standard to start with “x”. If it goes beyond “z”, I typically start again with “a”
- {}: When creating an R function, we use the braces to envelop everything contained within that function, all our commands
- val1–4: The commands that we’re including in our function. In this case, we’re multiplying, adding, subtracting and dividing x and y across different commands and creating different datasets in our function’s environment. You can call them whatever you want and run pretty much any command you like
- colnames(output): We’re telling R what the column names in our output frame should be. This isn’t always necessary, but can certainly be handy if you want specific column headers and your data doesn’t automatically support them
- output: An R function always returns the last value it creates, rather than everything in the function, so you have to be specific about what you want the output to be. Typically, you’d use “return” or “output” as your denotation, just for convention
You can have a lot of flexibility with your R functions, but following this general anatomy, your functions should work fine.
As we go through the rest of this series, we’ll be using functions quite a lot, and you’ll see that there are a number of different ways they can be invoked, but they’ll all follow this basic layout, so this should be a good grounding.
Now let’s look at certain commands that make our functions reproducible in different projects, and then we’ll start running through a couple of my favourite functions.
Using “Require” For Packages To Make R Functions Reproducible
As you go further on your R journey, you’ll inevitably find yourself re-using functions that you’ve written in other projects. But what if they depend on certain packages?
You can, of course, install those packages at the start of your project, but sometimes, it can be tough to remember which ones you used, which is why we can call them from our function directly. That’s where the “require” command comes in.
The require command does depend on you having installed the package in the past, so it’s not flawless if you’re sharing code, but at least with this notation in your function, you’ll know which packages you need.
Let’s do a function with our Google Analytics and Search Console commands from part 2, turning them into one dataframe with variable dates so we can re-use it easily.
If we authorised everything properly in the previous sessions, we shouldn’t need to go through that again, but you will still need your Google Analytics View ID to hand.
A Google Analytics & Search Console R Function With “Require”
Here’s how the function looks:
gaSCR <- function(x, y, z, a){
require(googleAnalyticsR)
require(searchConsoleR)
require(tidyverse)
ga_data <- google_analytics(viewId = x,
date_range = c(z, a),
metrics = c("sessions", "users", "pageviews", "bouncerate"),
dimensions = "date")
sc_data <- search_analytics(site = y,
start_date = z,
end_date = a,
dimensions = c("date"),
metrics = c("impressions", "clicks"))
merged_data <- merge(ga_data, sc_data, by = "date", all = TRUE)
merged_data$ctr <- (merged_data$clicks / merged_data$impressions) * 100
return(merged_data)
}
You’ll see at the start, that we’ve put “require” and named the packages that we’ll need for this piece. That means that, if they’re not already loaded in, R will load them whenever you run your function. However, they will need to have been installed previously.
Now we need to set our variables for x, y, z and a – our Google Analytics View ID, our Search Console website URL, our start date and our end date. If you go back to part 2, you’ll find how to do that.
For this example, I’ve used the following:
- x: view_id <- “GOOGLE-ANALYTICS-VIEW-ID”
- y: site_url <- “YOUR-WEBSITE-URL”
- z: start_date <- “YOUR-START-DATE”
- a: end_date <- “YOUR-END-DATE”
Now paste that into your console and follow it up with:
googleData <- gaSCR(view_id, site_url, start_date, end_date)
And there we go, a really handy R function for pulling Google Analytics and Search Console data into one dataframe with variable dates. Try it yourself and feel free to change it to include different metrics and dimensions.
How The Merged Google Analytics & Google Search Console Function Works
Let’s break it down:
- gaSCR <- function(x, y, z, a){: As always, we’re creating our function, naming it gaSCR and our variables are x, y, z and a
- require: Here, we’re telling R that there are packages required for this function to run, googleAnalyticsR, searchConsoleR and tidyverse, in this case. These will be packages you’ve installed before, if you’ve been following along, but if not, you’ll need to use the install.packages command for them
- ga_data <- google_analytics(viewId = x: We’re telling R to create an object called ga_data and it’s coming from the google_analytics function in googleAnalyticsR, focusing on our viewID variable which is x in this function
- date_range = c(z, a): As we saw in part 2, we’re invoking the date_range element of our Google Analytics call. We are combining our dates into our start date (z) and our end date (a)
- metrics = c(“sessions”, “users”, “pageviews”, “bouncerate”): We’re telling R that the metrics we want from Google Analytics are Sessions, Users, Pageviews and Bounce Rate. You can change these to your own requirements
- dimensions = “date”): The last part of our Google Analytics call is to split our data by dimension. Date, in this case
- sc_data <- search_analytics(site = y,: Now we’re starting our Google Search Console data pull, and our site URL is being invoked with y
- start_date = z, end_date = a: As with our Google Analytics call, we’re invoking our date range variables in our Google Search Console data
- dimensions = c(“date”): We’re splitting our Google Search Console data by date, in the same way we did our Google Analytics data
- metrics = c(“impressions”, “clicks”)): The metrics that we want from Google Search Console are impressions and clicks. That ends our Google Search Console call
- merged_data <- merge(ga_data, sc_data, by = “date”, all = TRUE): We’re using the merge function from the dply package in the tidyverse to combine our Google Analytics and Search Console datasets with the date being the anchor
- merged_data$CTR <- (merged_data$clicks / merged_data$impressions) * 100: Now we’re creating another column in our data which calculates click-through rate percentage
- output <- merged_data: Finally, we’re sending all this data to our output dataframe
Now we can see how to merge a Google Analytics and Google Search Console dataset within a singular dataframe. Pretty handy, right?
Note: This is still using Universal Analytics. I will be updating all these posts to utilise the GA4 API in the near future.
Now let’s look at a couple of my other favourite R functions that I find myself using a lot.
Merging Multiple CSV Files In R
This was one of the first functions I worked with outside of a course. It’s pretty old now, and I’m sure there are better ways to do it, but it still works reliably for merging multiple CSV files and getting them into your environment in R.
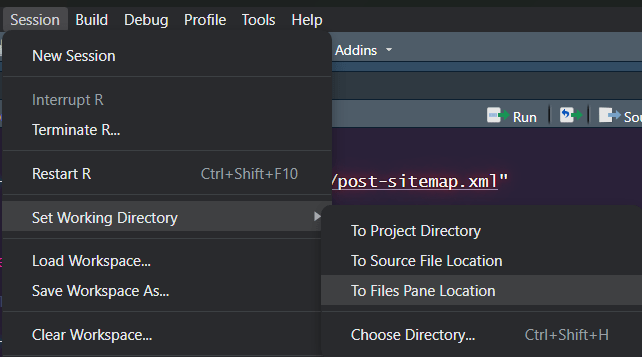
First, make sure your CSV files are all in one dedicated folder, preferably a subfolder of your project directory. You can navigate to them in RStudio through the “Files” pane, like so:

Now we need to tell R to switch our working directory to that, which we can do like so, using RStudio:
Alright, now we’re where we need to be, here’s the function I use to merge multiple CSV files in R and create a dataframe from them.
Before we continue, it’s vital that the CSV files all have the same headers. There can be different amounts of data in there, but if they’ve got different headers, this function won’t work. That said, I’ve found it really handy over the years for dealing with multiple exports and so on. Assuming all that’s true, here’s how to run it.
Paste the following into your console:
csvMerge <- function(x){
require(plyr)
csvFiles <- dir(pattern = x, full.names=TRUE)
output <- ldply(csvFiles, read.csv)
}
Now run it like so:
csvFiles <- csvMerge("csv$")
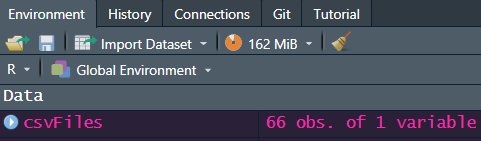
Depending on how many files and how big they are, it may take a few seconds, but it’s a lot quicker than copying and pasting in Excel! Now you should have a dataframe called “csvFiles” in your R environment like so:
Let’s break down how it works:
- csvMerge <- function (x){: We’re telling R that we’re creating a new object called csvMerge, it’s a function and there is one variable utilised called x. The opening brace is what the function’s commands will be contained in
- require(plyr): Our function has dependencies from the plyr package. If you don’t already have it installed, you’ll want to use the install.packages(“plyr”) command to get it installed. If you do already have it installed, this command will initialise it
- csvFiles <- dir(pattern = x, full.names=TRUE): Here, we’re telling R to look through the current working directory for files that match the pattern of our x variable, and that it should look at the full name of it. It should then create a csvFiles object with all of these names. In this case, our x variable is “csv$”, which means we’re looking for the end of the file to be called “csv”
- output <- ldply(csvFiles, read.csv)}: Our output is to use the ldply function from the plyr package to apply our chosen function (read.csv, in this case) across our list (csvFiles) and merge the results into a single dataframe. The closing brace says our function is complete
And there you have it: a quick and easy way to merge multiple CSV files in R. Even if you didn’t need them for analysis and just needed them all in one file, you can still use this function and then export it like so:
write.csv(csvFiles, “merged csvs.csv”)
This will export it all into one CSV file. I can’t tell you how handy this function has been to me over the years, so hopefully it’ll help you too.
Download XML Sitemaps & Check Status Codes In R
Obviously, there are better ways to do this, using tools like Sitebulb or Screaming Frog, but as SEOs, I’m sure we’ve all experienced the delays and challenges of software or getting IT departments to actually let us install them, which is why I created this little piece a while back.
This function downloads the XML sitemap from the target URL, scrapes the URLs from it using the Rvest package (another Hadley Wickham creation), and checks the HTTP status code of them using the httr package. Although sitemaps aren’t the be-all and end-all from an SEO perspective, it’s always worthwhile to have a clean one, free of redirects or broken links. Here’s how you can check your XML sitemap with R:
sitemapTestR <- function(x){
require(rvest)
require(httr)
sitemap_html <- content(GET(x), "text")
sitemap <- read_html(sitemap_html)
urls <- sitemap %>% html_nodes("loc") %>%
html_text()
results <- data.frame(url = character(), status_code = integer(),
stringsAsFactors = FALSE)
for (url in urls) {
response <- GET(url)
status_code <- status_code(response)
results <- rbind(results, data.frame(url = url, status_code = status_code,
stringsAsFactors = FALSE))
}
output <- results
}
It’s not the smallest of functions, but it works well.
How The SitemapTestR Function Works
Since this function is a bit of a beast and has a couple of elements we’ve not covered yet, I thought it was worth giving it its own section. As always, let’s break it down:
- sitemapTestR <- function(x){: As before, we’re naming our function – sitemapTestR in this case (see what I did there?), it’s got a single variable called “x” and we’re opening our braces to contain our commands
- require(: Again, we’re telling R that this function depends on the httr and rvest packages
- sitemap_html <- content(GET(x), “text”): We’re using functions from the httr package to run a GET request to request data from the server – the contents of the sitemap in this case, and we’re storing it as a text object
- sitemap <- read_html(sitemap_html): This part uses the read_html function of the rvest package to take the text we’ve just downloaded and turn it into html
- urls <- sitemap %>% html_nodes(“loc”) %>% html_text(): One of the great things about the Tidyverse and its associates is the ability to chain commands using %>%. In this example, we’re using it to say we want to create an object called “urls” using our “sitemap” object as the dataset, we’re using rvests html_nodes function (a command that pulls from the “nodes” of our sitemap – the markers called “loc”, which are the URLs in the XML sitemap) and take only the text within, which is what the html_text command does
- results <- data.frame(url = character(), status_code = integer(), stringsAsFactors = FALSE): This creates an empty dataframe called “results”, with the headers “url” and “status_code”, which are a character and integer respectively. We don’t want our strings to be seen as factors
- for (url in urls){: Here’s where we start to have some fun. We’re nesting a for loop inside our function. I’ve used loops in a couple of my other R language posts, but this is the first time we’ve used one in this series. There will be more to follow on loops in a later post, but here, we’re starting our loop with for, saying “for each url in the urls object, perform the commands below”. Similar to a function, these commands are contained in braces
- response <- GET(url): Using the httr packages’ GET request function, we’re putting the URL into an object called “response”
- status_code <- status_code(response): With our trusty httr package, our URLs status code is tested and added to an object called “status_code”
- results <- rbind(results, data.frame(url = url, status_code = status_code, stringsAsFactors = FALSE))}: Finally, the result of this test is added to our results dataframe with the URL entering the url column and the status code going into the status_code column, with no strings being factors. The rbind command says to merge them into a single frame as our loop runs these commands over every URL in our urls object and our closing brace finishes the loop
- output <- results}: And we’re finally finished with our function. Our output is the output frame from our results element of the loop and our closing brace finishes the function
Phew! I told you it was a beast of a function, but this is part of why we would use a function rather than interactive code. If you had a situation where you had to test several sitemaps, this could amount to hundreds of lines of code and hours of work, whereas this function allows you to run the same commands in a lot less time and with a lot less code.
Running The SitemapTestR Function
To run it, we need to create our x variable, which is the URL of our sitemap. Let’s use my posts sitemap as an example:
sitemap_url <- "https://www.ben-johnston.co.uk/post-sitemap.xml"
And to run it, we would use the following command:
sitemapStatus <- sitemapTestR(sitemap_url)
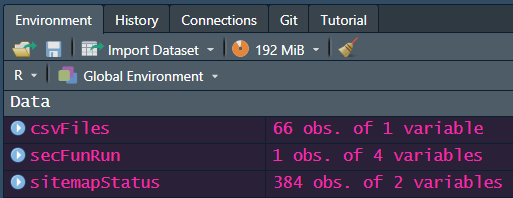
Give it a few seconds to run, and you’ll see the following in your environment:
Explore it with the str(sitemapStatus) command, and you should see the below:

And of course, you can export it to csv, with our trusty write.csv command.
write.csv(sitemapStatus, "sitemapStatus.csv")
And there we have it. Your XML sitemap tested in an R function. It’s certainly saved me some hassle over the years, and I hope it helps you too.
Strip URLs To Domains In R
This is a function that I use quite a lot, especially when doing link or competitor analysis using APIs in R (which we’ll cover in a couple of pieces time).
With this function, we take a URL from another column and strip it down to the domain using a very simple regular expression. This function has served me well for many years and uses an sapply method to run through a series of URLs. The function is as follows:
domainNames <- function(x){
strsplit(gsub("http://|https://|www\\.", "", x), "/")[[c(1, 1)]]
}
But we need some test data to run it on. If you go here, you’ll find a spreadsheet with the top-ranking URLs for the term “TV Units” from SE Ranking, which you can use for a test.
Stripping URLs To Domains With Our Test Data
Firstly, download the test data above and place it in your project folder.
Now read it in using the read.csv command as follows:
tvUnits <- read.csv(“tvUnits.csv”, stringsAsFactors = FALSE)
As I say, we’ll be covering how to pull this in directly from SE Ranking in a couple of weeks, but for now, this will work.
Now, after you’ve read your function into your R console, you can use the following command to strip the ranking URLs to domains in a new column in your dataset:
tvUnits$Domain <- sapply(tvUnits$URL, domainNames)
If we look at it using the str() command, we’ll see the following:
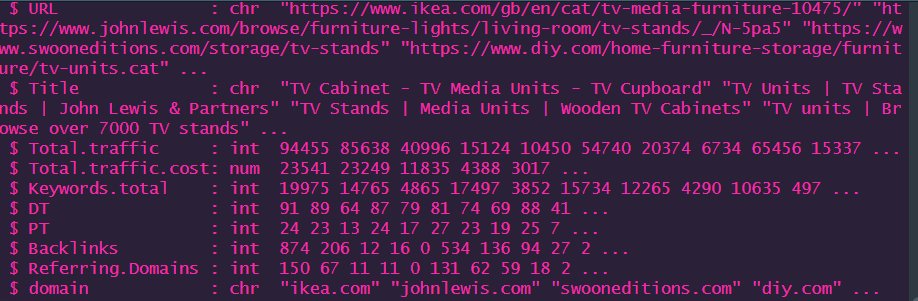
And there we have it. URLs stripped to domains using a fairly simple R function with no additional packages.
We’ll be talking about sapply and other apply methods in R in a few weeks, but for now, this means a “simple apply” and isn’t too dissimilar to a loop, in that it applies our function to every element in our list of URLs.
How It Works
While this function isn’t as large as our sitemap tester, there are still a couple of areas that we’ve not covered yet, so again, worth having its own section.
Let’s break it down.
- domainNames <- function(x){: As always, we’re creating a new function called domainNames and it has a variable called x
- strsplit(gsub(: We’re using the strsplit and gsub functions from base R. Strsplit – or “string split” means to break up a part of a string of text or numbers (our URL in this case) and gsub is effectively R’s way of invoking the classic find and replace
- “http://|https://|www\\.”, “”, x), “/”)[[c(1, 1)]]}: This intimidating-looking piece is actually a relatively simple regular expression which looks for everything before or after the domain name, including the http(s)://, the optional www. and everything after the domain name. Regular expressions are a great addition to any SEO’s skillset, either in your R journey or in general as they can be used for so many different elements. If you’d like to learn more about them, I love using the Slash\Escape game by Robin Lord as a training exercise
And that’s how you strip URLs to domains using R. Simple, elegant and very quick to run. It’s been very useful for me over the years and I hope it helps you too.
Wrapping Up
We’ve been on quite a journey today, haven’t we? Hopefully this has given you a good introduction to using R functions, particularly for SEO. There’re going to be quite a lot of functions in the next half of this series, so it’s worth becoming familiar with them.
I hope you’ve found this useful and that you’ll join me next time for part 5 where we’ll start replicating common Excel formulae in R. I promise this one won’t take me as long to post!
Our Code From Today
# First Function
firstFun <- function(x,y){
x*y
}
firstFun(5,2)
## First Function As An Object
firstFunRun <- firstFun(5,2)
# Second Function
secondFun <- function(x,y){
val1 <- x*y
val2 <- x+y
val3 <- x-y
val4 <- x/y
output <- data.frame(val1,val2,val3,val4)
}
secFunRun <- secondFun(5,2)
## Add Column Names To Second Function
secondFun <- function(x,y){
val1 <- x*y
val2 <- x+y
val3 <- x-y
val4 <- x/y
output <- data.frame(val1,val2,val3,val4)
colnames(output) <- c("multiply", "add", "subtract", "divide")
return(output)
}
secFunRun <- secondFun(5,2)
# Google Analytics & Search
ga_auth()
scr_auth()
gaSCR <- function(x, y, z, a){
require(googleAnalyticsR)
require(searchConsoleR)
require(tidyverse)
ga_data <- google_analytics(viewId = x,
date_range = c(z, a),
metrics = c("sessions", "users", "pageviews", "bouncerate"),
dimensions = "date")
sc_data <- search_analytics(site = y,
start_date = z,
end_date = a,
dimensions = c("date"),
metrics = c("impressions", "clicks"))
merged_data <- merge(ga_data, sc_data, by = "date", all = TRUE)
merged_data$ctr <- (merged_data$clicks / merged_data$impressions) * 100
return(merged_data)
}
## Using GA/ GSC Function
view_id <- "GOOGLE-ANALYTICS-VIEW-ID"
site_url <- "YOUR-WEBSITE-URL"
start_date <- "YOUR-START-DATE"
end_date <- "YOUR-END-DATE"
googleData <- gaSCR(view_id, site_url, start_date, end_date)
# Merge Multiple CSV Files
csvMerge <- function(x){
require(plyr)
csvFiles <- dir(pattern = x, full.names=TRUE)
output <- ldply(csvFiles, read.csv)
}
csvFiles <- csvMerge("csv$")
mergedCSV <- write.csv(csvFiles, "merged csvs.csv")
# Scrape & Test XML Sitemaps
sitemapTestR <- function(x){
require(rvest)
require(httr)
sitemap_html <- content(GET(x), "text")
sitemap <- read_html(sitemap_html)
urls <- sitemap %>% html_nodes("loc") %>%
html_text()
results <- data.frame(url = character(), status_code = integer(),
stringsAsFactors = FALSE)
for (url in urls) {
response <- GET(url)
status_code <- status_code(response)
results <- rbind(results, data.frame(url = url, status_code = status_code,
stringsAsFactors = FALSE))
}
output <- results
}
sitemap_url <- "https://www.ben-johnston.co.uk/post-sitemap.xml"
sitemapStatus <- sitemapTestR(sitemap_url)
write.csv(sitemapStatus, "sitemapStatus.csv")
# Strip URLs To Domain Names
domainNames <- function(x){
strsplit(gsub("http://|https://|www\\.", "", x), "/")[[c(1, 1)]]
}
tvUnits <- read.csv("tvUnits.csv", stringsAsFactors = FALSE)
tvUnits$domain <- sapply(tvUnits$URL, domainNames)
write.csv(tvUnits, "tvUnitsDomain.csv")



